[toc]
Conclusions
1 | WM --enhance-->LM |
局限:单一模型训练,需要提升泛化能力
Introduction
- LM在物理世界简单的推理和规划问题鲁棒性不足
- 引入新的训练范式Embodied Experiences from World Models (E2WM),使模型能够模拟物理世界的真实交互
- 两种collect embodied experiences的方法:面向目标和随即探索
- EWC_LoRA 降低训练成本

Related Work
- World Model:物理世界的可计算表示,模拟世界状态变化响应各种动作。
- 本文使用VirtualHome作WM。
- Language Model Grounding:大量工作聚焦在将语言模型建立世界模型之上。
- Language Model Regularization:为了在不损失LM的语言建模能力的情况下促进新知识和技能的获得,在微调期间经常引入正则化。
Approach
- 提出新范式E2WM:在不损失LM语言建模能力的情况下,向LM中注入具体知识。
- WM:VirtualHome
- 行动可用元组[action]
表示
- 行动可用元组[action]
Collecting Embodied Experiences from World Model
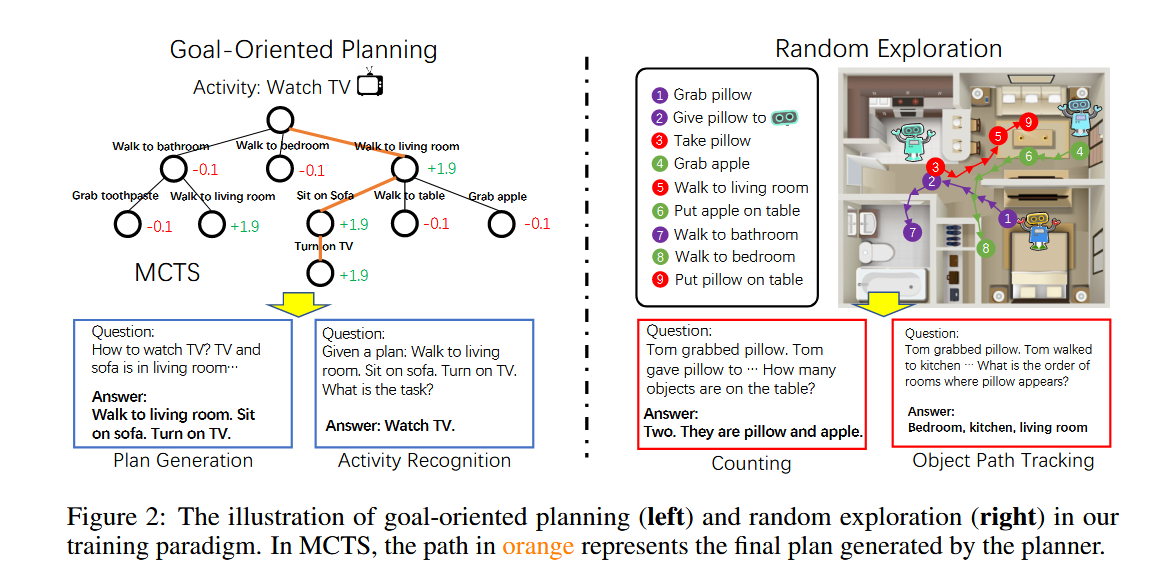
Goal-oriented Planning
- 设计了一个蒙特卡洛树搜索(MCTS)规划器来搜索整个动作空间,并找到一个计划,即一系列动作,以实现目标。
- MCTS成功的关键是奖励设计。
- 成功获得+2奖励,并从目标中移除。
- 在每个时间步骤之后,它将得到-0.1的惩罚,以阻止planner采取与实现目标无关的行动。
- 最后,我们将规划过程存储为具体体验。
Random Exploration
在世界模型中部署一个或多个智能体,无目的地漫游并随机执行动作。
Finetuning LMs with Embodied Experiences
面向目标的计划生成编译成两种数据格式:
- plan generation :给定一些相关对象的状态作为初始条件,该模型需要生成一个逐步的动作序列来完成活动。
- activity recognition:,模型需要根据其计划识别活动名称。
随机探索获得的经验转化为两个有监督任务:
- counting:在智能体执行相关和不相关的动作并随机排列对象之后,在特定位置识别对象的数量和名称。
- object path tracking:模型的任务是输出由不同智能体拾取并在不同时间移动到不同房间的对象的移动路径。
使用交叉熵损失进行训练。
$$L_V = \sum_{v∈V} α_v \sum _{m=1}^M log P (y_m|y<m, x),$$
- L损失函数,V任务序列,α任务权重、通过为不同任务分配不同的权重来微调语言模型。、
Efficient Finetuning with Preserved Generality
存在问题:
- 过拟合
- 资源消耗大,时间成本高
解决:
- 使用低秩适配器(LoRA)和弹性权重合并(EWC)来微调少量权重
EWC:
- 正则化方法
- 计算fisher矩阵来估计任务的每个参数的重要性,然后使用它来正则化新任务的训练。通过约束新任务的参数更新,来避免忘记先前的知识。
(3).png)
- F:fisher矩阵,θ:当前参数 and$$θ^∗_U$$:冻结参数
- (2)通过对任务U的梯度平方和求平均来计算fisher矩阵,这表示每个参数对任务U来说的重要性。
- 通过使用EWC,LM学习适应新任务,而不会对预训练任务产生灾难性遗忘,这迫使它从微调任务中理解和消化新知识,而不是过度拟合它们。
- 问题:EWC时间和内存效率低下。
- 微调整个大LM参数集。
- 需要创建一个冻结的原始模型和一个与LM大小相同的fisher矩阵,导致原始大小的三倍的内存开销。
LoRA:
为了解决上述问题引入。与EWC结合使用。
冻结预处理的模型权重,并将两个可训练的低秩矩阵注入模型的每一层。
.png)
$$W = W^∗ + BA$$
W权重矩阵,$$W^*$$权重参数冻结矩阵,A、B低秩矩阵,H=AB,$$h_i = θ_i − θ^∗_U$$为H的参数
EWC-LoRA不需要存储整个权重矩阵,只需要存储低秩矩阵 H,从而节省了大量的内存空间。同时,由于只需要更新低秩矩阵中的参数,训练速度也得到了显著提升。
Experiments
Downstream Evaluation Tasks
Plan Generation
- Plan Generation Evaluation
- Housework QA
- Negation Housework QA
Activity Recognition
- Activity Recognition QA
- Activity Inference QA
Counting
- Counting QA
Object Path Tracking
- Object Path Tacking Evaluation
- Object Location QA
Results
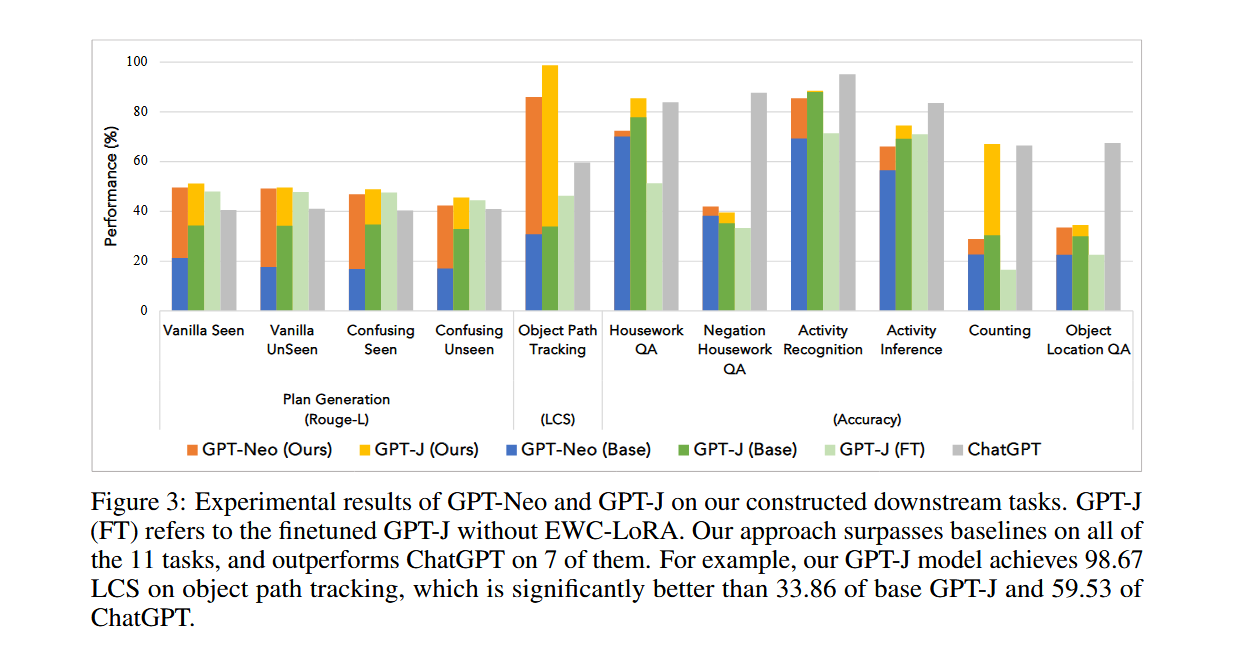
图3展示了GPT-Neo和GPT-J在构造的下游任务上的性能对比。图中显示了不同任务的性能百分比,包括计划生成、活动识别、计数、对象路径跟踪等。从图中可以看出,经过世界模型微调的GPT-Neo和GPT-J在所有任务上的性能都显著优于基线模型(Base),并且在某些任务上甚至超过了ChatGPT。
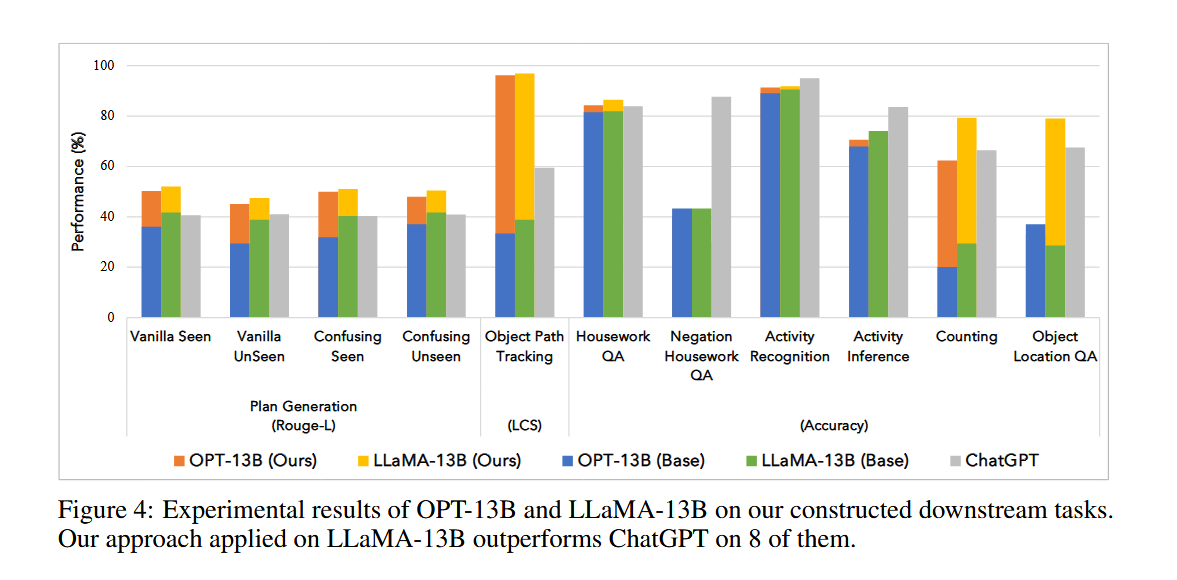
图4展示了OPT-13B和LLaMA-13B在构造的下游任务上的性能对比。图中的任务和评估指标与图3相同。结果显示,经过世界模型微调的OPT-13B和LLaMA-13B在所有任务上的性能都显著优于基线模型(Base),并且在某些任务上甚至超过了ChatGPT。
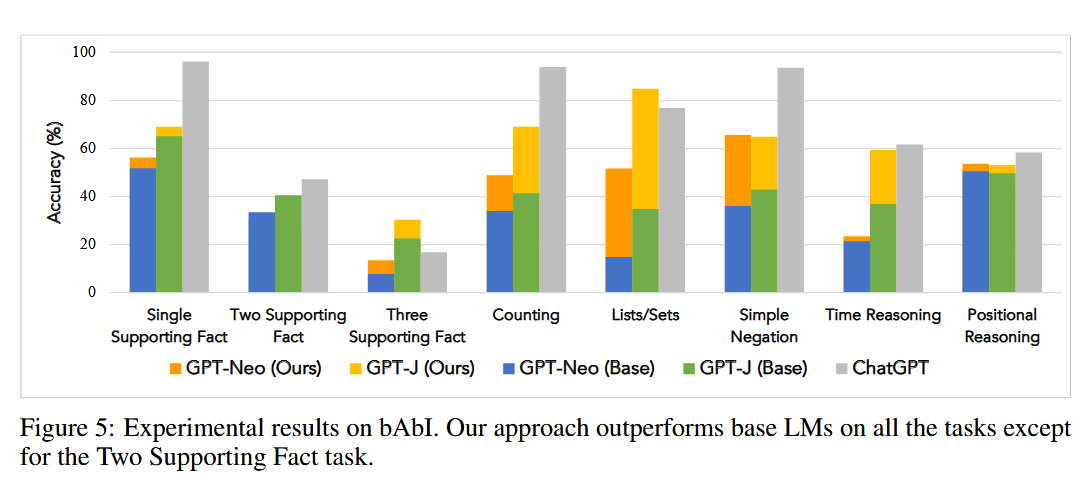
图5展示了不同模型在bAbI数据集上的性能。bAbI数据集包含多个任务,每个任务测试不同的知识和能力,包括支持事实、计数、列表/集合、简单否定、时间推理和位置推理。结果显示,经过世界模型微调的GPT-Neo和GPT-J在所有任务上的性能都显著优于基线模型(Base),并且在某些任务上甚至超过了ChatGPT。
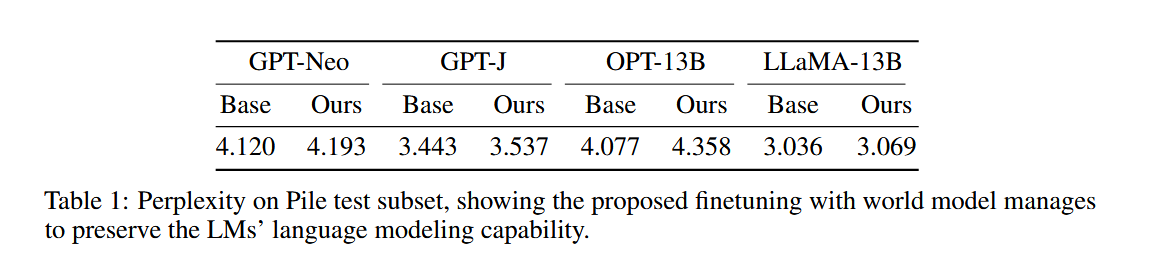
表1展示了不同模型在Pile测试子集上的困惑度结果。困惑度是衡量语言模型在预测下一个词时的不确定性的一个指标,数值越低表示模型的预测能力越强。从表中可以看出,经过世界模型微调的模型在困惑度上略有增加,但增加幅度非常小,表明这些模型在保持语言建模能力方面表现良好。
Comparison of Different Regularization Methods
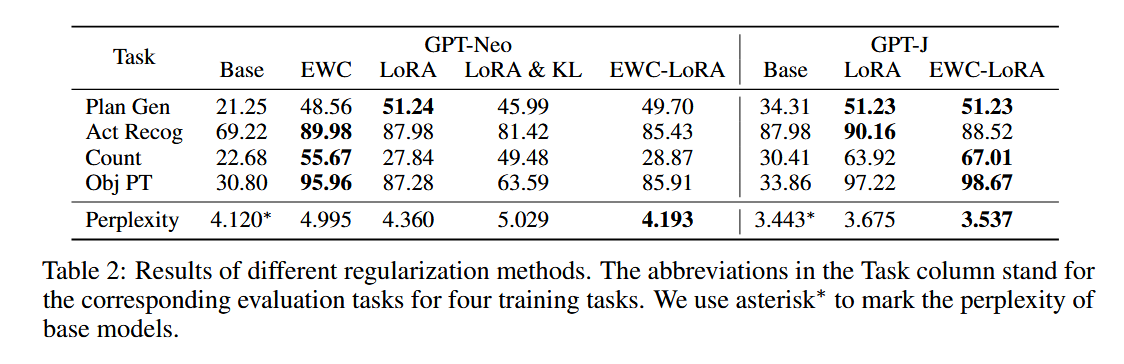
表2展示了不同正则化方法在四个评估任务上的性能对比。
- Base: 基线模型。
- EWC: 使用弹性权重巩固(Elastic Weight Consolidation)的模型。
- LoRA: 使用低秩适配(Low-Rank Adaptation)的模型。
- LoRA & KL: 使用低秩适配和KL正则化的模型。
- EWC-LoRA: 使用弹性权重巩固和低秩适配的模型
从表中可以看出,EWC-LoRA方法在所有任务上的性能都显著优于其他方法,并且在困惑度上也表现最佳。
Ablation Studies
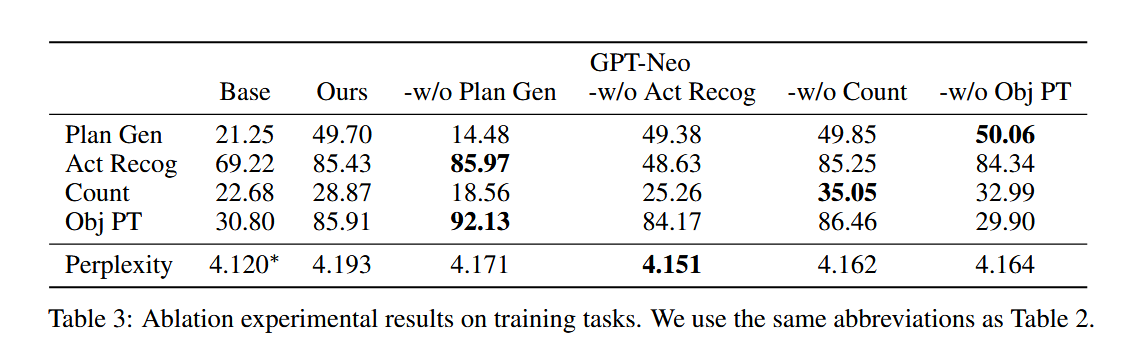
删除具有类似能力的训练任务会导致模型在下游任务上的性能显著下降。有趣的是,当计数从训练任务中省略时,计数QA性能会增加,这可能是因为计数能力可以从其他训练任务中推断出来。
创新点
- 提出新的训练范式(E2WM):引入了一种新的语言模型训练范式,即通过世界模型收集具身经验来增强语言模型。这种方法突破了传统语言模型仅依赖文本训练的局限,使模型能够获得物理世界的知识和技能。
- 多样化的具身经验收集:通过目标导向规划和随机探索两种方式收集具身经验。目标导向规划使模型学会规划和完成特定目标,而随机探索则帮助模型获得对象永久性和跟踪等认知能力,为语言模型提供了丰富的物理世界交互经验。
- 有效的微调策略(EWC-LoRA):结合了弹性权重巩固(EWC)和低秩适配(LoRA)的方法,在微调语言模型时既保留了模型的通用性,又显著降低了训练开销。这种策略不仅提高了训练效率,还减轻了灾难性遗忘的问题,使模型能够在不遗忘先前知识的情况下学习新任务。
优化
- 计算效率提升:尽管EWC-LoRA方法在一定程度上降低了计算开销,但还可以进一步探索更高效的参数更新机制和训练策略,以适应更大规模的模型和更复杂的任务。
- 模型融合:可以考虑将E2WM方法与其他先进的语言模型训练技术相结合,如对比学习、自监督学习等,以进一步提升模型的性能和泛化能力。
If you like this blog or find it useful for you, you are welcome to comment on it. You are also welcome to share this blog, so that more people can participate in it. If the images used in the blog infringe your copyright, please contact the author to delete them. Thank you !